Java 编程基础
这是一篇面向Ruby语言编程者的培训文档,主要介绍Java语言的基本概念和编程技巧。
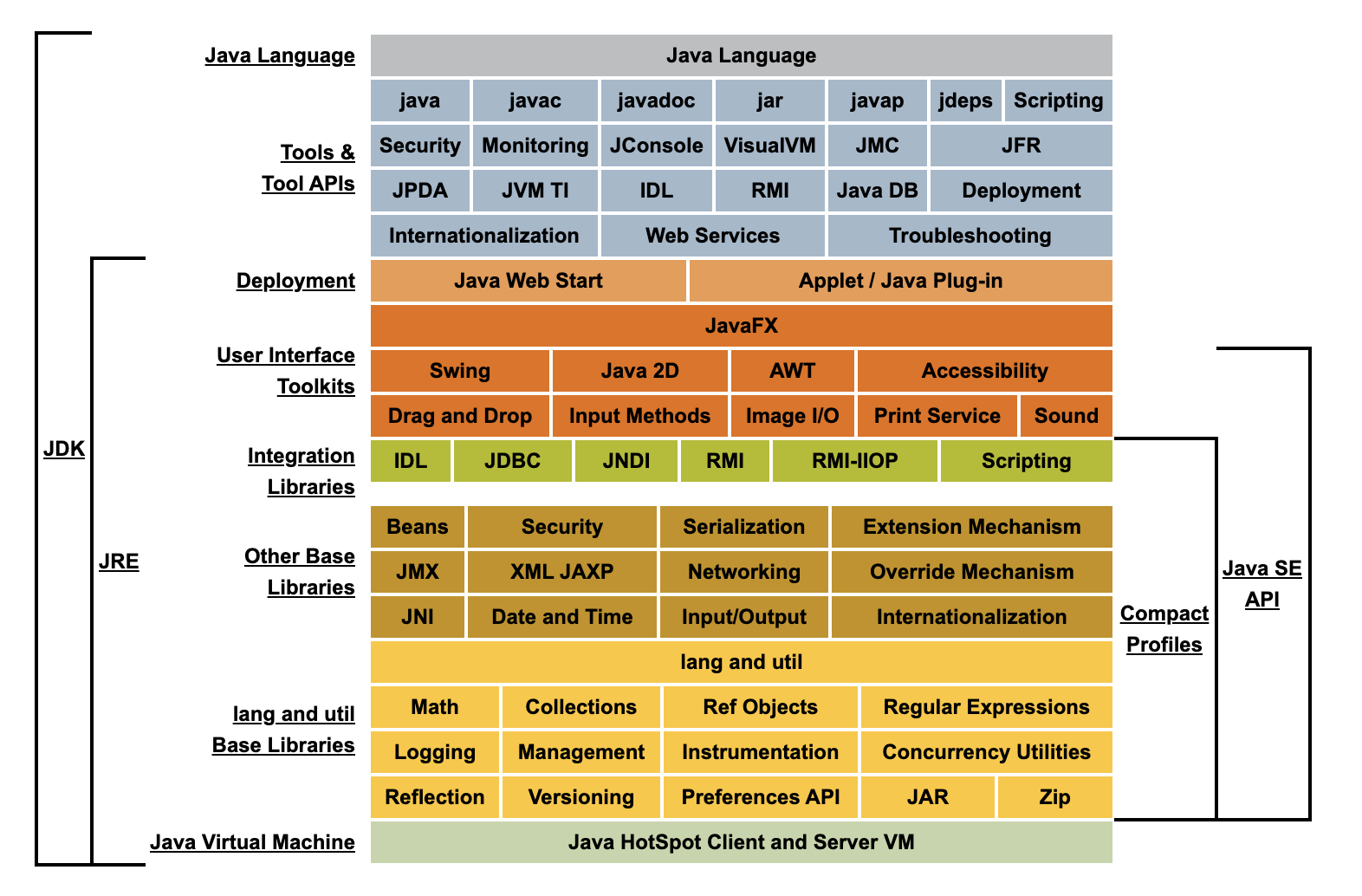
JDK、JRE和JavaSE
JRE(Java Runtime Environment),Java运行环境,与Ruby Core类似,主要提供Java核心类库和JVM。由于只是运行环境,JRE不可用于源代码编译。
JDK(Java Development Kit),Java开发者工具,除核心类库外,还提供编译、运行、调试等工具。JDK9及以前的版本中,jre不再作为一个独立文件存 在jdk目录下。下载IDEA会自带openJDK,但有个缺陷是没有Javadoc,所以我还是建议自行去Oracle官网下载JDK,可以很方便查看各类接口的文档和设计说明。
JavaSE(Java Standard Edition),Oracle提供的标准版JDK,与前文提及的JDK比,缺少JavaFX、Swing、WebService等桌面编程和Web应用类库。 但桌面应用时代已过去,JSP等技术也成为历史垃圾,所这些存在于JavaEE(Java Enterprise Edition)的库对互联网时代的微服务开发没有什么帮助
JVM
JVM(Java Virtual Machine),Java语言跨平台运行的依赖,所有源码通过 javac 编译后,形成的字节码文件通过JVM调用操作系统资源。JVM是一种规范, 基于此规范有不同实现,主要的实现有HotSpot,基于硬件和实现算法的趋同,JRE8以后,HotSpot已经只提供一种实现,即Server VM。Scala、Groovy、 Kotlin等编译后的字节码能被JVM识别的语言都可以借助JVM运行,甚至实现与Java语言的互调。
日常编程中,与JVM相关比较重要的点有内存模型JMM(Java Memory Model)和GC(Garbage Collection)。
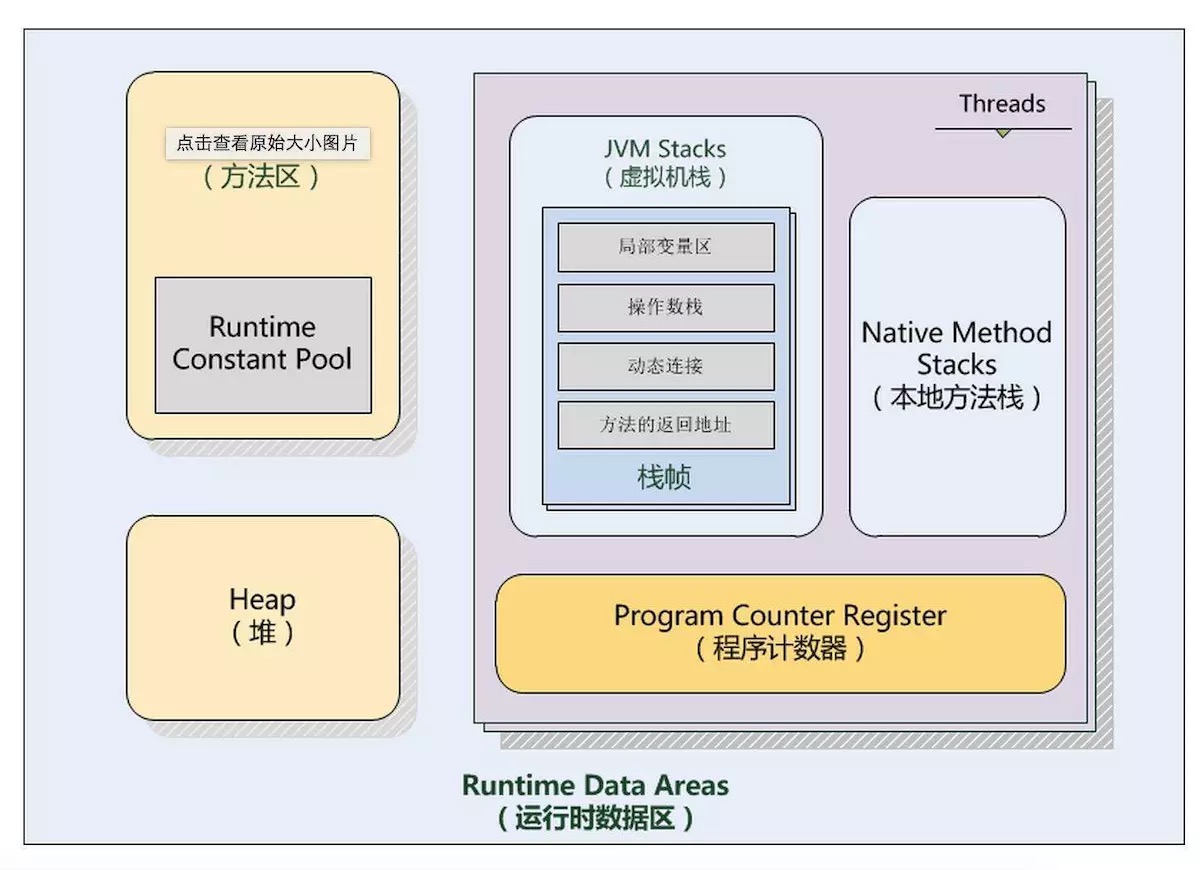
JMM
简单地说,Java的内存分为两部分,线程独有的栈和线程共享的堆,栈内的对象占用的内存随线程结束而释放,堆中的内存依赖于垃圾回收。细分下来,栈主要由
虚拟机栈(随线程创建)、本地方法栈、程序计数器组成;堆分为新生代、老年代、永久代(即方法区,存储加载的类基本信息和常量,JRE8以上的实现已经以MetaSpace替
代永久代PerGen,主要是引入操作系统内存代替固定分配的JVM内存来保存加载信息,实现内存动态分配)、运行时常量池(保存-128到127的整数,直接声明或调用了
String.intern函数的字符串等)。
Java的多线程模型与Ruby不同,可以利用多核cpu实现并发,所以内存模型和线程安全问题也更重要。在Ruby中,全局锁GIL机制保证了在常见的编码场景,如单 一函数内、非I/O场景下,类的实例对象和全局对象的线程安全,这使得Ruby编码过程中,大部分情况不用考虑有状态(stateful)类的线程安全问题。但Java中不 一样,当任意两个线程运行同一段代码时,Java没有默认的机制去保证线程安全(原子性、有序性、可见性)。对于有序性,Java只有一个简单的happens-before原则:
- 程序顺序规则:一个线程中的每个操作,逻辑上happens-before于该线程中的任意后续操作。
- 监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。
- volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。
- 传递性:如果A happens-before B,且B happens-before C,那么A happens-before C。
- start()规则:线程的start操作happens-before于线程中的任意操作。
- join()规则:线程中的任意操作happens-before于其他线程的join操作成功返回。
- 程序中断规则:对线程interrupted()方法的调用先行于被中断线程的代码检测到中断时间的发生。
- 对象finalize规则:一个对象的初始化完成(构造函数执行结束)先行于发生它的finalize()方法的开始。
多线程编程
基于内存模型,在Java编码过程中,涉及有状态类的处理,也需要时刻注意这个原则。常用处理方式有四种:
- 用volatile修饰类属性,volatile关键字通过内存屏障,保障修饰对象的可见性和有序性,所以此方式仅适用于原子性操作(如赋值运算,而++、+=不具有原子性)
- 用synchronized关键字修饰相关代码块,synchronized关键字通过对象的monitor锁,保障修饰目标的原子性、可见性和有序性,避免编译过程中的重排序。 如果锁住类的Class对象,可以锁住类的所有实例
- 借助JUC(java.util.concurrent包)框架下的Lock组件,如ReentrantLock、ReadWriteLock等实现类,或自行实现一个Lock实例,可以借助 AQS(AbstractQueuedSynchronizer)类
- 借助ThreadLocal类保存需要并发修改的对象,这些对象会与当前线程绑定,也可以用于跨对象传值
如果只是处理一些简单并发问题,如并发计数等,可以借助JUC框架一些工具类,如AtomicInteger、ConcurrentHashMap等。
多线程的实现方式有很多,简单的异步场景可以通过三种方式实现:
- 继承Thread类,并重写run方法。Java内的线程都是基于Thread类创建的,但Java遵循单继承、多实现的设计,所以这是一种既不优雅,也不便捷的实现方式。 大部分业务场景下,不推荐使用,除非实现依赖许多线程相关操作时,可以采用这个方法。
- 实现Runnable接口。Runnable接口只有一个run函数,会在线程启动后执行,在不需要得知线程执行结果的情况下可以使用这个方式。
- 实现Callable接口。Callable接口提供一个范型参数和一个call函数,call函数执行完成时,需要指定一个范型参数类型的返回值,这个值可以通过 Future接口获取,适合需要获取线程执行结果的场景
public class MultiThread {
static long threadId(){
return Thread.currentThread().getId();
}
static void sleep(long millis){
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
static class ThreadA extends Thread{
@Override
public void run(){
System.out.println("ThreadA-" + getId() + " is running!");
MultiThread.sleep(1000);
System.out.println("ThreadA-" + threadId() + " has stopped!");
}
}
static class RunnerA implements Runnable{
@Override
public void run() {
System.out.println("RunnerA-" + threadId() + " is running!");
sleep(1000);
System.out.println("RunnerA-" + threadId() + " has stopped!");
}
}
static class CallerA implements Callable<Integer>{
@Override
public Integer call() throws Exception {
System.out.println("CallerA-" + threadId() + " is running!");
sleep(1000);
System.out.println("CallerA-" + threadId() + " has returned!");
return 666;
}
}
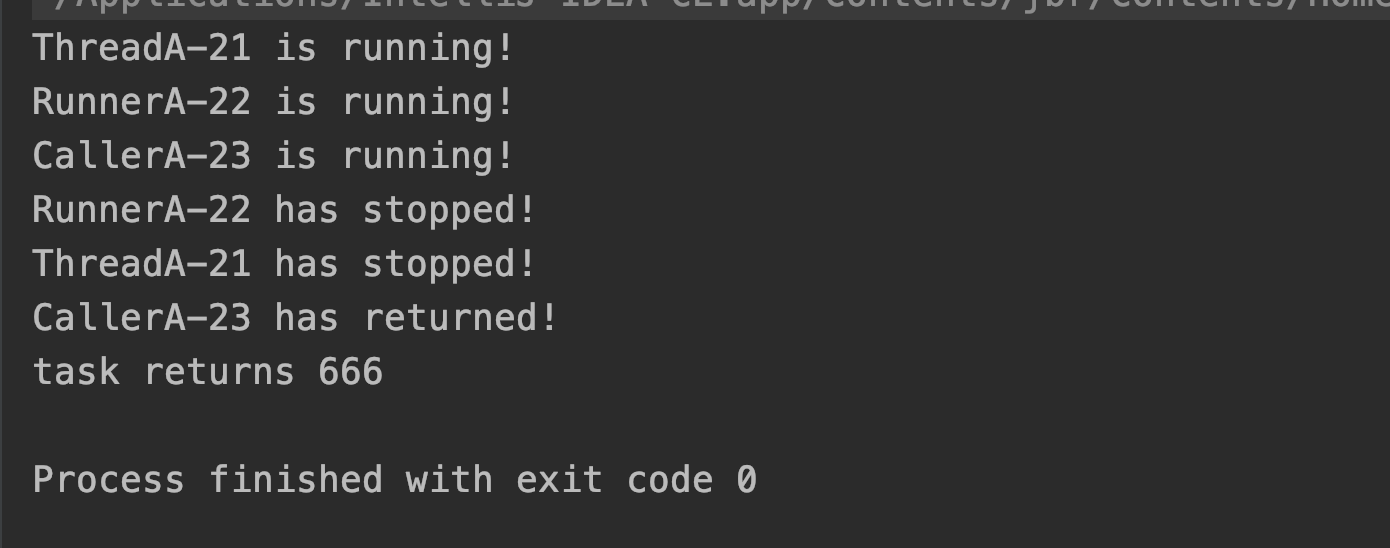
public static void main(String... args){
// 继承方式实现多线程
ThreadA threadA = new ThreadA();
threadA.start();
// 实现Runnable接口
RunnerA runnerA = new RunnerA();
new Thread(runnerA).start();
// 实现Callable接口,需要配合FutureTask或ExecutorService框架实现
CallerA callerA = new CallerA();
FutureTask<Integer> task = new FutureTask<>(callerA);
new Thread(task).start();
try {
System.out.println("task returns " + task.get());
} catch (Exception e) {
e.printStackTrace();
}
}
}
在稍微复杂一点的场景下,例如线程需要重复利用,或者需要获取多个线程结果,可以使用JUC的框架 ExecutorService,它是常用线程池模型 ThreadPoolExecutor的接口,Spring等框架也基于此接口提供许多实现。
public class Main {
public static void main(String... args) throws Exception {
ExecutorService threadPool = Executors.newFixedThreadPool(10);
VolatileCounter counter = new VolatileCounter(0);
List<VolatileCounter> counters = new ArrayList<>(1000);
for (int i = 0; i < 1000; i++) {
counters.add(counter);
}
long start = System.currentTimeMillis();
List<Future<Integer>> futures = threadPool.invokeAll(counters);
futures.forEach(o -> {
try {
System.out.print(o.get() + " ");
} catch (Exception e) {
e.printStackTrace();
}
});
long end = System.currentTimeMillis();
System.out.println("\ntask time cost: " + (end - start) + "ms");
threadPool.shutdown();
System.out.println("counter: " + counter.counter);
}
static class VolatileCounter implements Callable<Integer> {
volatile int counter = 0;
VolatileCounter(int counter) {
this.counter = counter;
}
@Override
public Integer call() {
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
return ++counter;
}
}
}
 利用Executors构造了一个10个核心线程的线程池,每个线程执行暂停50ms,1000个线程顺序执行需要50000ms,而结果显示任务结束仅耗时5258ms,说明10
个线程的并发度确实达到了。从程序结果中我们可以印证volatile关键字无法保证原子性。
利用Executors构造了一个10个核心线程的线程池,每个线程执行暂停50ms,1000个线程顺序执行需要50000ms,而结果显示任务结束仅耗时5258ms,说明10
个线程的并发度确实达到了。从程序结果中我们可以印证volatile关键字无法保证原子性。
这里有个细节是,运行程序的硬件是8核cpu,在超线程技术下,可以算作最多16个线程并行执行。理论上,线程池核心线程超过16后,任务运行耗时是不会再下降的,
也就是至少耗时3125ms,加上线程初始化、上下文切换和代码运行时间,耗时会更多。但实际情况是,我们把线程池核心线程数调整为1000的话,任务耗时会下降
到170ms,不是理论值3125ms,也不是设置的线程睡眠时间50ms。这是因为Thread.sleep()函数在调用时,会让出cpu时间片,交给其他线程使用,线程
状态进入TIMED_WAITING,该线程在等待时间内,不会再竞争cpu,所以这1000个核心线程不受16个cpu限制,可以看作在并行执行。而之所以耗时在170ms而不
是50ms,是因为cpu调度过程中,线程上下文切换的耗时无法避免。如果我们将上面代码中的call函数使用synchronized关键字修饰起来,无论核心线程数多大,
耗时都会是50000ms,因为synchronized关键字会使得当前执行线程持有对象的monitor锁,而Thread.sleep()函数只让出cpu时间片,却不会释放线程持有的锁。
public synchronized Integer call() {
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
return ++counter;
}
 这个结果也侧面印证synchronized关键字保证修饰对象的原子性。
这个结果也侧面印证synchronized关键字保证修饰对象的原子性。
GC
垃圾回收是许多高级语言的特性,对于Java而言,垃圾回收主要作用于JMM堆区中的新生代(Young Generation)和老年代(Old Generation),主要通过根搜索 算法和标记计数算法对不再使用的对象进行清除,并对内存空间进行压缩,减少内存碎片。而MetaSpace(旧称方法区/永久代,也包括常量池)因为自身特性,垃圾回 收主要面向无引用的常量,以及对已无任何实例或类加载器已被卸载的Class类信息进行卸载,第二个特性可用于一些动态字节码生成的场景,卸载动态类占用的内存。 对具体的GC算法不进行展开,我们只需要关心一下GC在实际编程中可能出现的应用。
首先需要了解三个概念,逃逸分析、栈上分配和TLAB:
- 逃逸分析:一种计算引用作用域的算法,通过连通图和引用可达性分析,在创建对象前,判断对象为全局逃逸、参数逃逸和不会逃逸三种状态,不会逃逸的对象可以 直接进行栈上分配。逃逸分析将对这类对象进行标量替换(将基本类型和Reference直接分配在栈帧或cpu的寄存器内,提高访问效率)和同步消除(创建对象时不需要获取同步锁)。
- 栈上分配:顾名思义,直接使用栈内存创建对象,不将对象分配在堆内存中,因此对象会随着线程结束而直接摧毁
- TLAB:Thread Local Allocation Buffer,这是内存分配的一片缓冲区,不是前文提及的ThreadLocal。每个线程创建对象时,会在新生代中开辟一片 TLAB,用来分配一些小对象(当然,ThreadLocal所引用的对象在创建时可能也会分配在这里)。TLAB是线程私有的,因此不需要在分配时对新生代进行加锁,但面 向的对象是无法进行栈上分配的。TLAB默认只占新生代(Eden:Survivor1:Survivor2 = 8:1:1)Eden区的1%,被占满时线程就必须向Eden申请空间,如果 Eden空间不足,则触发Minor GC;如果垃圾回收后空间依然不足,则直接分配到老年代。JVM默认开启TLAB,-XX:-UseTLAB参数可以关闭。
public class EscapeAnalysis {
private static Integer GLOBAL_COUNTER; // 全局静态变量
String name; // 私有属性
public String random() {
GLOBAL_COUNTER = new Integer(0); // 赋值给全局变量,全局逃逸
Character[] chars = new Character[10];
Random seed = new Random(); // 局部引用,未发生逃逸
chars = Arrays.stream(chars).map(o -> (char) (seed.nextInt(26) + 'a'))
.toArray(Character[]::new);
String random = Arrays.toString(chars); // chars 作为参数调用,局部逃逸
name = random; // random 赋值给属性,局部逃逸
return random; // 作为返回值,局部逃逸
}
}
使用1000个线程创建10000000个对象,测试TLAB的作用,开启状态下,耗时约6000ms,关闭状态耗时9000ms,开启时性能有明显提升。
public static void main(String... args) {
long start = System.currentTimeMillis();
int nThread = 1000, n = 10000000;
ExecutorService threadPool = Executors.newFixedThreadPool(nThread);
Collection<Callable<Object>> callers = new ArrayList<>(100);
List<Object> list = new ArrayList<>(n);
for (int i = 0; i < n; i++) {
callers.add(() -> {
list.add(new Object());
return null;
});
}
try {
threadPool.invokeAll(callers);
threadPool.shutdown();
} catch (InterruptedException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
System.out.println("\ntime cost: " + (end - start) + " ms");
}
基于逃逸分析和栈上分配的概念,我们大概知道了对象分配的生命周期。基于GC,需要再介绍Java引用的概念:
- 强引用:所有直接的赋值运算都是强引用,强引用的对象只有在根搜索算法查询不到时,才会被回收,否则一直存在于老年代中,直到内存不足抛出异常
- 软引用:SoftReference关联的引用,与强引用相比,软引用对象在内存不足时会被GC回收。在用到大链表等场景下,可以考虑使用。
- 弱引用:WeakReference关联的引用,与软引用相比,弱引用在每次GC执行时都会被回收。在用到大链表等场景下,可以考虑使用。
- 虚引用:PhantomReference关联的引用,必须与引用队列ReferenceQueue关联,可在对象被回收时,加入引用队列。实际编码过程中几乎不用。
JVM 11的可达性分析已经非常成熟,实际编码过程中用到的工具类,基本不需要手动置空以达到协助GC的目的。如果有自行实现的链表或树等数据结构, 置空相关引用可以协助垃圾回收。参考
Object类
作为面向对象编程语言,Java的Object像Ruby一样,是所有类的父类。Object类中,有以下方法可供子类使用:
- getClass():获取当前类的类对象,通常在一些判断和反射场景下用到
- hashCode():JNI地方法生成一个整型的hashCode,主要应用于依赖散列算法的地方,如HashMap。hashCode相等是对象相等的必要不充分条件
- equals():判断两个对象是否相等,主要应用于Map、Collection等。重写此函数同时应该重写hashCode()函数,两个对象应该有相等的hashCode
- clone():获取该对象的深复制
- toString():将对象转化为字符串,数据实例可以重写此函数进行默认序列化
- notify()、notifyAll():唤醒一个/所有因此对象monitor锁进入WAITING状态的线程
- wait():使持有该对象monitor锁的当前线程进入WAITING/TIMED_WAITING状态,直到被唤醒或等待时间结束
- finalize():在对象被GC时,此函数会被执行。Java9及之后的版本已废弃
常用开发工具类
Java是个强类型语言,虽然新的feature已经支持类型推断和弱类型声明,但Java的本质没有改变。一些规定是很死板的,如JavaBean属性需定义为私有, 只能通过getter/setter向外部暴露值。基于这些客观事实,Java许多语法会显得极其繁琐,因此需要借助各类工具来提高开发效率。
- lombok:这是一个字节码增强工具,通过注解的方式,节省数据类代码,如
@Data、@Getter、@AllArgsCounstructor、@Builder、@Slf4j、@NonNull等 - Objects:JDK的Objects工具类,提供了equals()、nonNull()、compare()等一系列工具函数
- Arrays:JDK的Arrays工具类,提供数组相关操作,如asList(...)、singleton()、stream()等
- Collections:JDK的Collections工具类,提供集合类增强,如sort()、addAll()等
- System:JDK的系统类,提供系统层面的接口,比如arrayCopy()、gc()等
- Math、Random、Decimal:JDK的数学运算相关类,提供诸如其名的工具。需要进行浮点运算时,应使用Decimal的实现替代double、float等浮点类型
- ObjectUtils、StringUtils:这里主要是说Spring框架的增强类,此工具类封装了诸如isEmpty()、nullSafeEquals()等判断工具,可以避免难看的空指针判断
除了上面列出的,还有许多开源库提供的工具类。这里建议以最少依赖原则引入第三方库,这样便于统一代码风格,也在一定程度上避免包冲突。
Lambda表达式和Stream API
Lambda表达式和Stream API对开发者来说,是JDK8最有意义的特性之一,它极大简化了编码复杂度。Stream API针对集合数据,产生一次该集合的复制,对集 合原有数据不会造成任何影响。但计算过程中的数据就像流水一样,每个元素只能获取一次,想要再次获取,必须创建一个新的流。
import org.springframework.util.CollectionUtils;
import org.springframework.util.StringUtils;
import java.util.*;
import java.util.stream.Collectors;
public class LambdaDemo {
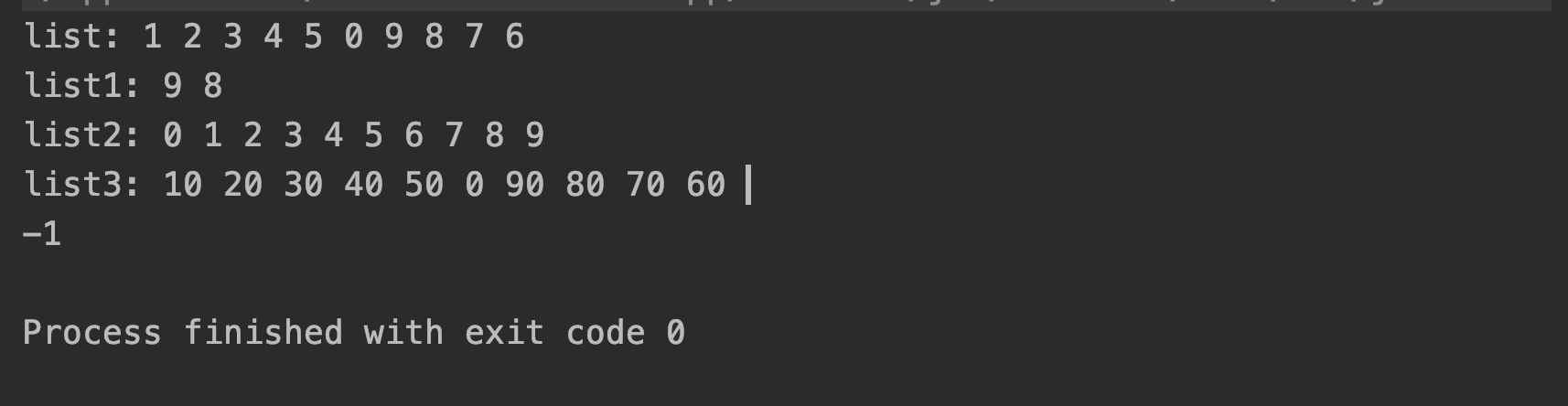
public static void main(String... args) {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5, 0, 9, 8, 7, 6);
// filter() 选取Lambda表达式结果为true的结果,collect() 根据Collector收集结果
List<Integer> list1 = list.stream().filter(o -> o > 7).collect(Collectors.toList());
printCollection("list", list);
printCollection("list1", list1);
// sorted() 排序,可传入一个排序函数式接口
List<Integer> list2 = list.stream().sorted().collect(Collectors.toList());
printCollection("list2", list2);
// map() 对每个元素做计算,并返回计算结果
List<Integer> list3 = list.stream().map(o -> o *= 10).collect(Collectors.toList());
printCollection("list3", list3);
// findFirst()/findAny() 获取第一个/任意一个元素,返回一个Predict函数接口,接口判断不存在时,返回orElse的结果
int i = list.stream().filter(o -> o < 0).findFirst().orElse(-1);
System.out.println(i);
}
private static void printCollection(String name, Collection collection) {
if (StringUtils.isEmpty(name) || CollectionUtils.isEmpty(collection)) {
return;
}
System.out.print(name + ": ");
collection.forEach(o -> System.out.print(o + " "));
System.out.println();
}
}
 JDK8的Lambda表达式、Stream API、函数式接口还有许多应用场景,如匿名函数,函数式接口回调等。如果对此语法不熟悉,调整IDEA的语法标准(File->Project
Structure->Modules->Language Level)为Java8及其以上,打开语法检查,IDEA会根据语言标准对可优化的代码进行提示,从而帮助熟悉新的语法特性。
JDK8的Lambda表达式、Stream API、函数式接口还有许多应用场景,如匿名函数,函数式接口回调等。如果对此语法不熟悉,调整IDEA的语法标准(File->Project
Structure->Modules->Language Level)为Java8及其以上,打开语法检查,IDEA会根据语言标准对可优化的代码进行提示,从而帮助熟悉新的语法特性。
接口、注解、反射、范型
接口:前面提到,Java语言遵循单继承、多实现的设计,因此不得不提接口(interface)。接口通常是一系列行为的集合,编程中用来声明一些函数,多个模 块互相调用时,通过接口的方式进行,而不关心具体实现,这是常见的面向接口编程思想。例如Java声明的Collection接口,ArrayList、LinkedList、 HashSet等类都是该接口的实现,它们有数组、链表、HashTable等不同的实现方式。但当我们使用诸如Stream API、Collections工具类,去进行一些操作, 比如排序时,我们只需要关心自己的排序算法的实现,而不需要关心排序对象的实现,因为获取元素的行为已经被Collection接口封装起来,我们调用排序API时, 只需要将排序对象向上转型为Collection接口就好。此外,基于这样一种固定的声明的特性,因此在RPC服务中,Java的接口通常用来作为二方包发布。
注解:注解是一类特殊的接口,它的声明方式是@interface,要使注解可以使用,需要指定注解的@Target和@Retention的值。
注解中只能声明各类行为,以及这些行为的默认返回值,但无法让具体的类去实现它。在编码过程中,我们可以在类、属性、方法、参数等地方使用注解,由@Target
的值决定;@Rentention的三个值决定了注解的生命周期,分别是Source(只在源码中可见,编译过程会忽略)、Compile(编译器会将注解
编译到class文件中)和Runtime(注解被编译到class文件中,同时可以在JVM运行时通过反射获取)。
反射:反射是Java获取类的元数据,也就是Class对象数据的一种方式。通过Class对象,我们可以获取类的属性、方法、方法的参数、注解等所有class文件 内保存的数据。基于这些数据,如方法Method,反射API提供声明式的调用,这个特性使我们只知道类限定名、字段名、函数名等场景下,可以通过名称直接调用。 这是一种灵活的设计,在JRE多次改良后,反射的执行效率已经非常高。许多基于字节码和动态类加载的框架,如ORM,使用反射进行实现。JDK提供的动态代理框架 Proxy,也是通过反射调用增强后的动态类实例,以达到代理的目的。
范型:范型是Java提供的一种编码手段,可以认为范型是针对类的一种变量,代码中的范型变量在编译时会被实际使用的类型取代。范型出现以前,类似 Collection这样的接口声明只能用Collection
public class GenericsDemo<T1, T2> {
T1 t1;
T2 t2;
<M extends Map<T1, T2>> GenericsDemo(M map) {
if (map == null) return;
map.forEach((k, v) -> {
t1 = k;
t2 = v;
});
}
T1 getT1() {
return t1;
}
T2 getT2() {
return t2;
}
}
Maven
Maven是款Apache提供的Java项目构建工具,集依赖管理、编译、测试、打包、发布等功能于一身,是最常用的Java开发工具。maven的基本生命周期如下:
- clean:清理classPath内的文件,通常在target目录下。如果运行时发现程序结果和自己的预期不符,可以执行
mvn -U clean强制清理已存在的包试试 - validate:验证所有资源文件的完整性
- compile:编译源码到classPath
- test:执行单元测试
- package:将编译完的字节码文件打包,形成jar或war等可直接被jvm执行的程序
- verify:运行检查,不常用,具体流程待验证
- install:将打包完成的包部署到本地maven仓库(默认~/.m2/repository)下,供不同模块依赖,常用于多模块依赖项目
- site:生成站点,不常用,具体流程待验证
- deploy:部署项目的包到依赖的远程仓库,可用于二方包发布、覆盖等
maven可以管理多个模块,每个模块都需要自己的pom.xml文件。pom文件主要包括以下属性:
- parent:依赖的父级包
- groupId:jar包的groupId,通常为公司/组织前缀+项目名称,如 cn.xg.study
- artifactId:jar包的artifactId,通常唯一标识项目模块名称,如 main-server
- version:jar包的版本号,groupId:artifactId:version 三个值组合一起,形成当前项目jar包唯一标识
- properties:设置一些局部或全局属性,可通过 ${} 占位符进行调用
- dependencyManagement:依赖管理配置,主要用于确定每个依赖包的版本,此项不会为当前项目加载被声明的包,但管理的值可以被所有子项目继承
- dependencies:当前项目依赖的包,声明项会被maven加载。如果发生依赖冲突,可以通过exclusions子项排除。依赖冲突是最常见的问题,判断冲突的方
式可以使用
maven dependency的结果对比,但这很低效,IDEA有个maven-helper插件,可以协助对比冲突 - build:maven作为构建工具的核心,可以引入各类插件来增强maven的构建能力
- modules:当前项目所包含的子模块