揭开大模型的面纱
基本信息
简介
大语言模型(Large Language Model)是一种用于自然语言处理的计算模型,擅长实时问答、内容生成、总结归纳等任务。基于 Transformer ,LLM与传统NLP模型的区别是,在提供足够多的训练文本后,LLM能够像人一样,“理解”这些自然语言的内容,包括情绪、专有名词、上下文信息等传统NLP技术难以处理的内容,甚至像人一样在“理解”信息后,给出具备较强逻辑的回应。
需要说明的是,LLM本质依然是基于概率学的深度学习,是一种 Sequence To Sequence 处理技术,其本身不具备类似人的逻辑和运算能力。LLM之所以看起来具备一定逻辑能力,是因为提供给它的训练文本,其本身的顺序中就包含了人类的表达逻辑。LLM只是将这些逻辑结果保存下来,并在需要的时候,通过概率,将可能性最高的答案计算出来。
历史
语言模型相关的技术历史已有超过30年,而直到2022年才被公众知晓、重视,这是一个量变引起质变的过程。
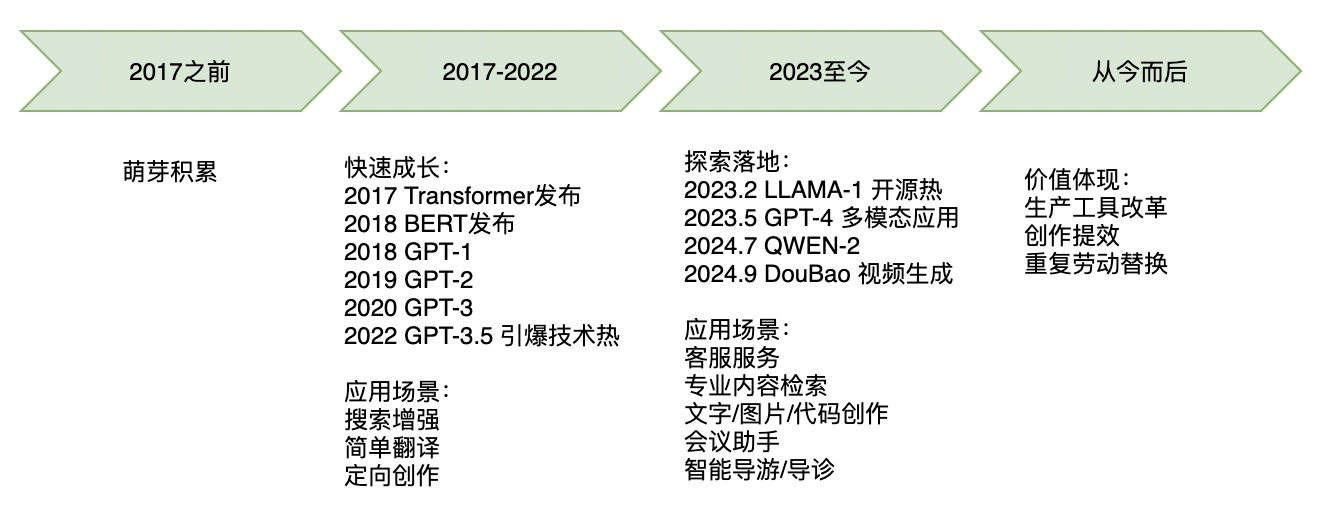
LLM不一定是20年代最具突破性的技术,但一定是让大众重新认识到科技改变生活的技术。
技术架构
整体应用架构
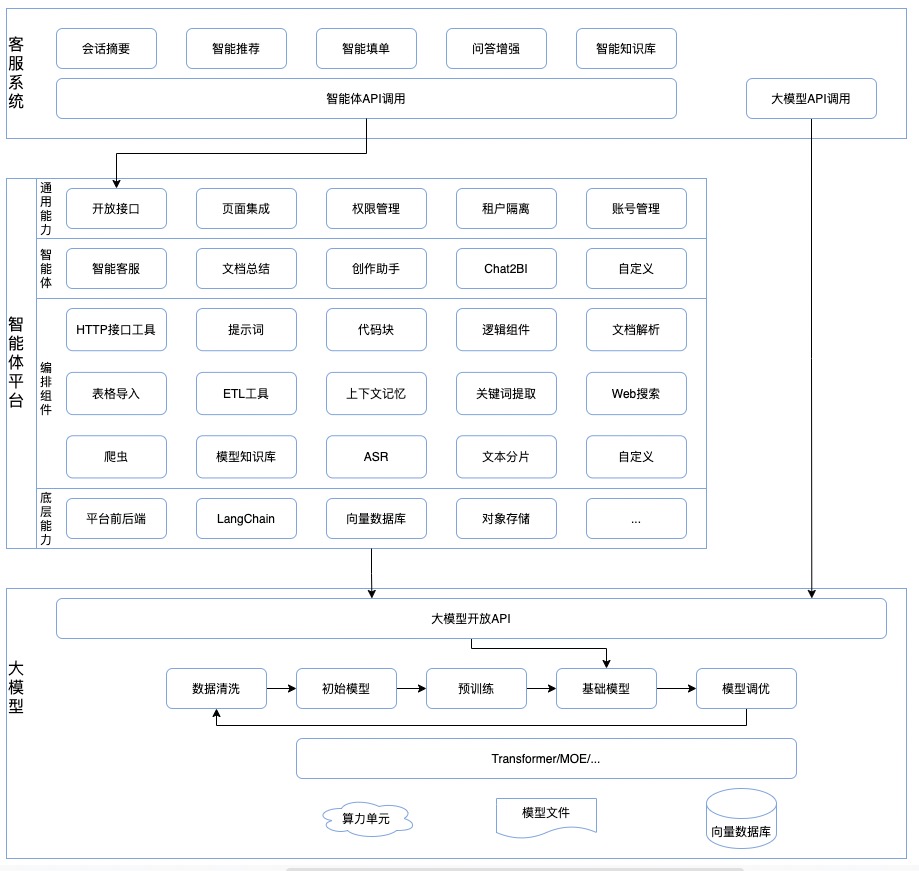
在细分去讲大模型应用架构前,我想先从具体的业务场景出发,和各位介绍一下一个大模型应用是怎么落地实现的。通常,一个大模型应用分为三部分:业务系统、智能体平台 和 大语言模型 。
业务系统 :包括所有业务场景对大模型的接入、业务数据准备、业务流程适配、大模型API封装等,一些prompt调用可以封装在业务系统内。
智能体平台 :提供丰富的流程编排工具,用于实现大模型调用的封装,实现一些通用逻辑或业务逻辑。除调用流程外,智能体平台通常还提供 RAG 等基础能力,以提升大模型对业务场景的适配度。与业务系统直接对接大模型对比,智能体平台的优势是具备丰富的组件,可以灵活地实现流程编排;基于 LangChain 、 LlamaIndex 之类的大模型调用框架,也能更简单地实现大模型能力调度。一个好的智能体平台,除了具备完善的账号、租户隔离机制,最重要的是提供足够丰富的编排组件。
大语言模型 :基础模型,经过数据清洗、模型初始化、预训练、调优后,具备了足够的推理能力,能根据输入的文本提供合理的生成式输出。大语言模型是一个“大力出奇迹”式的结果,因此预训练模型的数据质量,决定了大模型的生成质量。一些垂直领域的模型,会在通用知识预训练后,使用行业知识进行二次调优,以提升基础模型本身对于专业知识的应答质量。
以当下我们在开展的智能客服系统为例,以下是其系统架构:
Transformer 架构
主流大模型大多基于 Transformer ,这是一个从有序输入中学习,并生成有序输出的神经网络框架。从输入到输出, Transformer 会经历如下步骤:
Tokenization: 分词,原始文本被转换成模型能够处理的数值形式,为后续的Embedding步骤做准备。 如将“我有一只猫”,分词为 ["我","有","一只","猫"]Embedding: 嵌词,将分词结果转化为GPU可运算的向量,通过向量运算能快速获取词汇间的关联关系Positional encoding: 位置编码,在第二步嵌词的基础上,将词汇的位置信息嵌入到词汇向量中,使运算结果具备顺序逻辑。如果缺失这一步,可能出现“爱江山,更爱美人”与“爱美人,更爱江山”在大模型中表示为同一个意思的问题。Transformer block: 转换器流程,通过对嵌词和位置编码的结果进行反复的转换运算,计算出与输入相关的向量数据,作为最终输出的可选项。Softmax: 归一化,对于第四步转换产生的可选结果,归一函数通过数学运算,整合所有可选结果并形成最终输出
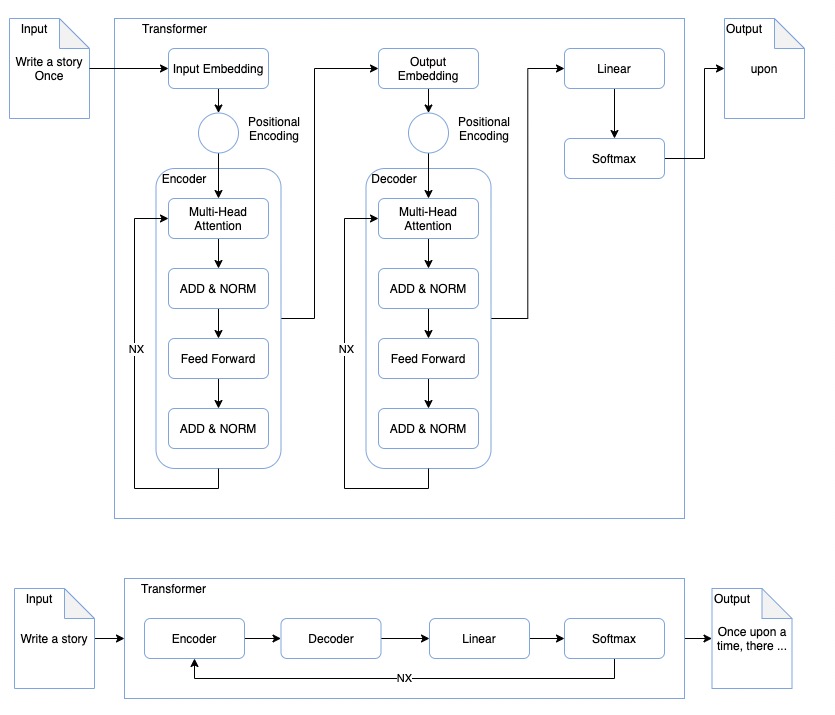
我们以让大模型写一个故事为例,对Transformer 的架构做一个简单介绍。
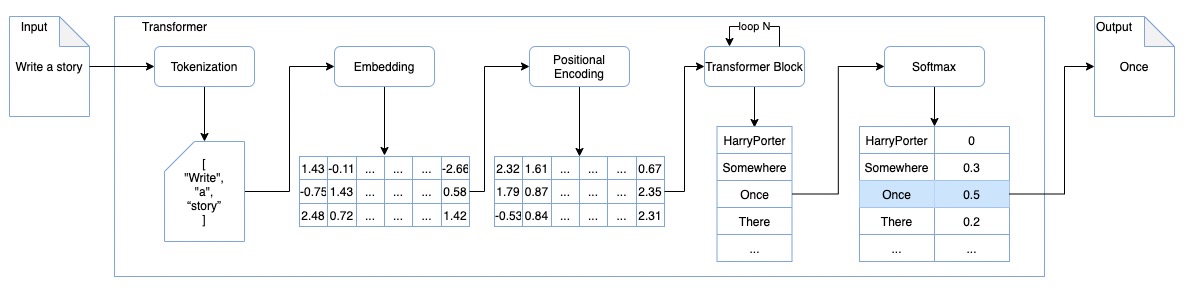
我们让大模型写一个故事,通过对输入数据的处理,大模型的第一次任务在训练的数据中找到了最高可能的一个生成结果"Once"。未停止生成的情况下,大模型会带着这个结果进一步执行生成任务,直到任务执行完成。
数学原理
对编程不熟悉的朋友,可能不太理解向量、矩阵和线性转换这些概念,因此无法理解为什么应用架构中要用到向量数据库,以及 Transformer 架构中为什么需要将数据转换为向量再进行计算。下面我们简单说明一下。
向量
我们以数学中最简单的二维坐标系为例,简单解释一下向量、矩阵和线性转换之间的关系。
在数学中,向量的定义是:一个具有大小和方向的量,如二维坐标中,从 A(x1,y1) 到 B(x2,y2) ,表示为 B-A=(x2-x1,y2-y1) 。将所有向量平移到以原点 (0,0) 出发,我们可以非常简单得看出两个向量间的关联关系。
如有向量 , 我们可以轻易判断 的关联度,比 的关联度高。
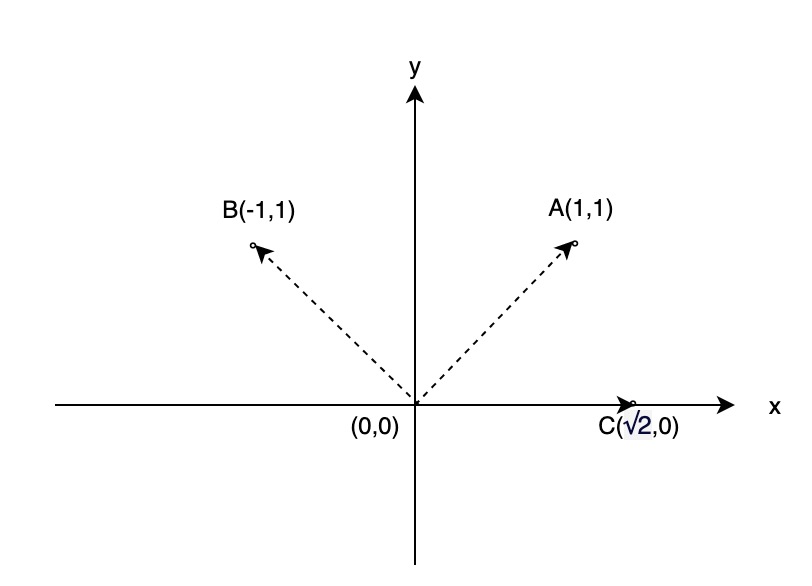
那么从数学上,我们怎么定义两个向量的关联度或者说相似性呢?通常有两种计算方式:点积 和 余弦积 。
点积:点积是衡量向量相似度的最常用方法,这种计算将夹角和模长同时纳入考量,能够充分体现两个向量间的关系。
, 和 垂直
,由于 和 的模长均为 ,可得 ,即
余弦积:余弦积是对点积的归一化计算,其结果将模长恒定为1,仅计算向量夹角的余弦值。
矩阵
向量:向量通常被看作是一个一维数组,或者更具体地说,是一个具有方向和大小的量,可以用有向线段来表示。在线性代数中,向量经常被表示为列向量或行向量,即一个n×1或1×n的矩阵。
矩阵:矩阵是一个二维数组,由m×n个数排列成的m行n列的矩形表格。特别地,一个m×1矩阵也被称为一个m维列向量,而一个1×n矩阵则被称为一个n维行向量。
如将上图二维空间中的三个向量 用矩阵表示,则为 行矩阵:
或列矩阵:
在日常生活中,二维、三维向量容易被人理解,但高维向量就难以有一个直观的认知了。将向量表示为矩阵,即是为了让计算机更快得运算,也是一种将抽象问题简易化的方式。
线性变换
线性变换 是操作向量的一种手段,它的定义有点晦涩,我们以前面的二维空间为例。我们将 逆时针旋转 变成 ,这个过程保持了 原点不变 且 仍为直线 ,这就是一种线性变换。
线性变换 与 矩阵 又有什么关系呢?
前文我们提到向量本身可以表示为矩阵,即 = 。 如果定义一种矩阵表示 和计算规则 ,使得 ,则可完成整个线性变换的矩阵表示,这其实就是 矩阵乘法。
在二维空间中,令
如
业务链路
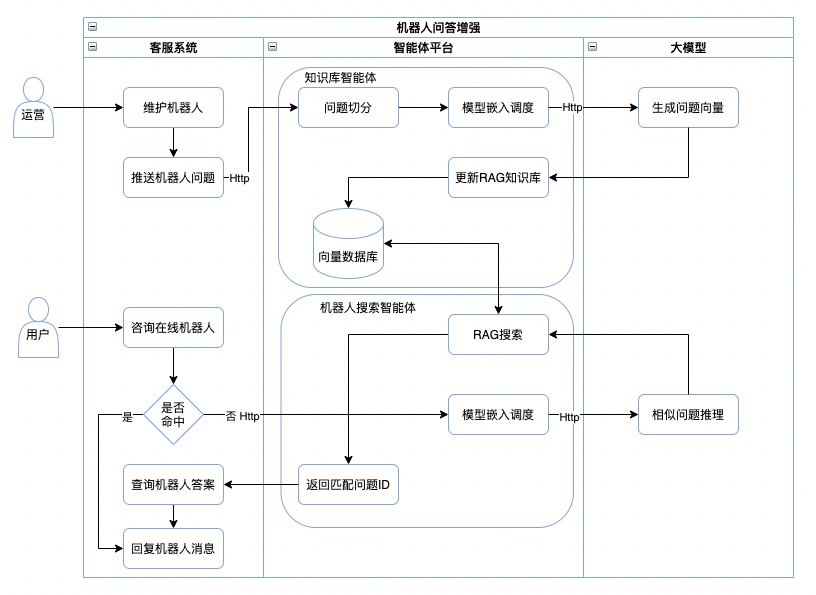
以客服系统问答增强场景为例,我们简单分析一下业务场景的调用链路。
调用链路
整个调用流程大致分为两部分,涉及两个智能体:
- 机器人问题维护
- 用户咨询机器人
机器人问答增强流程
数据安全
大模型调用的数据安全是各方都比较关注的事情,以问答增强的场景为例,我们解释一下与数据安全相关的一些场景。 整个调用链路中,数据安全大致分为两个方面:传输 和 计算 。
传输
以上场景中,传输涉及两部分:
- 业务系统到智能体平台
- 智能体平台到基础模型
这两个调用流程,均基于 Http/Https 协议,规避常见的 SSL 攻击即可解决传输过程中的安全问题。若对数据安全要求较高,双端调用时,建议使用 AES 等协议对业务数据进行加密传输。
计算
更多的安全隐患存在于计算过程中,对于智能体平台,数据泄漏可能出现于以下场景:
- 数据权限不完善,访问到跨账号数据
- 内存隔离模型不完善,跨线程数据泄漏
针对这些场景,通常有以下解决方案:
- 完善多租户体系
- 所有查询语句增加租户ID限制,提供行级别数据隔离
- 按照租户分表/分库,提供表/库级别数据隔离
- 支持业务数据库按用户配置,访问用户自己的数据库
- 完善线程隔离模型
- 采用线程安全的框架(如
Actor),通过独立线程完成计算;采用操作系统消息、管道等数据传输机制,避免使用内存共享 - 采用多进程架构,每个运算分配独立的内存,运算结束后销毁
- 采用线程安全的框架(如
- 私有化部署智能体平台
- 直接调用大模型,避开智能体平台
对于大模型本身,由于推理涉及算力,服务器成本较高,大多数公司不会采取私有化部署模型的方式,因此数据安全只能从模型计算下手。
对于基础模型,从Transformer 架构这一节,我们知道进行 Embedding 后的数据是向量的数值形式,失去了数据的敏感性,因此数据泄漏主要发生在 Tokenization 环节。
对于分词环节,避免数据泄漏的方案和前文提及的一样,完善线程隔离模型。
总结
站在解决业务问题的角度出发,一个好的大模型固然重要,但一个扩展性强的智能体平台才是大模型应用落地的关键。我们可以从业务系统直接调用大模型实现部分场景,但是缺少智能体平台的支持,每个业务系统需要重复实现流程编排、调优等事项,长远来看是一个巨大的资源浪费。利用好智能体平台的通用工具和编排能力,能大幅降低业务系统自身的复杂度与耦合度。
因此,在模型本身差异不大、难以区分的情况下,决策团队应该优先考虑智能体平台的能力。